What was once easy, is now exceptionally convoluted and difficult. There is some chance that your automated script is already logging to the event log (PowerShell Core/Operational) but there’s every chance that log is full of Warnings too. Good luck. LOL
New-WinEvent
The New-WinEvent cmdlet creates an Event Tracing for Windows (ETW) event for an event provider. You can use this cmdlet to add events to ETW channels from PowerShell.
The Get-WinEvent cmdlet gets events from event logs, including classic logs, such as the System and Application logs. The cmdlet gets data from event logs that are generated by the Windows Event Log technology introduced in Windows Vista and events in log files generated by Event Tracing for Windows (ETW). By default, Get-WinEvent returns event information in the order of newest to oldest.
The post below is the deprecated way of interacting with the Event Log from PowerShell. In Powershell 7 onwards, use New-WinEvent and Get-WinEvent cmdlets.
The command Get-Command -Name *Event will still list the deprecated commands shown below but they will not work and will error with “The term ‘New-EventLog’ is not recognised as a name of a cmdlet…”
The command Get-Command -Name *WinEvent will list the supported cmdlets, namely New-WinEvent and Get-WinEvent
PowerShell Commands to interact with Windows Event Log
Creates a new event log and a new event source on a local or remote computer. This cmdlet creates a new classic event log on a local or remote computer. It can also register an event source that writes to the new log or to an existing log.
Displays the event logs of the local or a remote computer in Event Viewer. The Show-EventLog cmdlet opens Event Viewer on the local computer and displays in it all of the classic event logs on the local computer or a remote computer.
Show-EventLog [[-ComputerName] ] []
Clear-EventLog
Clears all entries from specified event logs on the local or remote computers. The Clear-EventLog cmdlet deletes all of the entries from the specified event logs on the local computer or on remote computers. To use Clear-EventLog, you must be a member of the Administrators group on the affected computer.
Writes an event to an event log. To write an event to an event log, the event log must exist on the computer and the source must be registered for the event log.
Sets the event log properties that limit the size of the event log and the age of its entries. The Limit-EventLog cmdlet sets the maximum size of a classic event log, how long each event must be retained, and what happens when the log reaches its maximum size. You can use it to limit the event logs on local or remote computers.
Deletes an event log or unregisters an event source. The Remove-EventLogcmdlet deletes an event log file from a local or remote computer and unregisters all its event sources for the log. You can also use this cmdlet to unregister event sources without deleting any event logs.
Top Tip: You may already have a Function in your script to perform Logging to a file. You could augment it to include some code to add an event to the Windows event log depending on the outcome of the script or code loop.
Did you like this? Tip cyberfella with Cryptocurrency
This is the simplest method of automating ftp operations from PowerShell that I can come up with, having explored MANY incredibly convoluted alternatives.
It is an absolute minimum viable product that can be built upon, consisting of two downloadables that compliment one another and eight commands that probably do everything you need, and do it in a single command.
A link to the wiki for all the cmdlets is given in step 10 below.
Once the WinSCP module is installed, interfacing with an FTP server is as easy as this…CerberusFTP Server displaying the inbound session from PowerShell using WinSCP cmdlets that call WinSCP .NET Assembly winSCPnet.dllDon’t forget to close the ftp session when you’re done….….and the session disappears from Cerberus FTP Server.
0. Download Software
Download matching versions of the Assembly and Cmdlets (5.17.10.0). The most recent version of the Automation .NET Assembly is 5.19.6.0 but you may have issues talking to WinSCP 5.19.6.0 using version 5.17.10.0 Cmdlets such as New-WinSCPSession where it complains about the winscp.exe version not matching the winscpnet.dll version.
Additional commands required for Secure FTP (SSH Hostkey Fingerprint)
The example above was kept as simple as possible to demonstrate the minimum number of steps in order to “get things working”. Now we can build upon those steps and establish an sftp connection to the FTP Server.
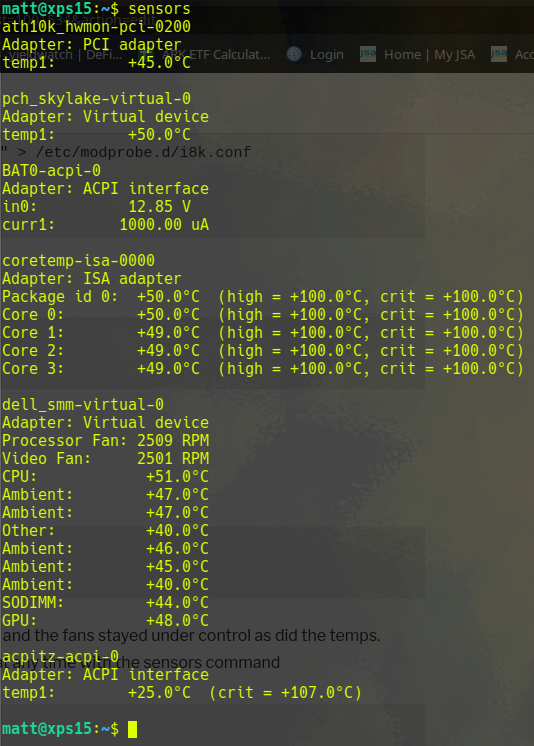
I left the config file at the defaults and the fans stayed under control as did the temps. check the temps and fan speeds at any time with the sensors command
sensors
45 – 50 degrees C and 2500 RPM fan speeds whilst running Brave and Virtual Box
Did you like this? Tip cyberfella with Cryptocurrency
This will allow you to install those specific containerised versions of apps that you want, e.g. Whatsdesk (a containerised Whatsapp client for your Linux desktop).
sudo snap install whatsdesk
Did you like this? Tip cyberfella with Cryptocurrency
Note that this only applies if you’re using a swapfile as opposed to a swap partition. This will apply if you’re using full disk encryption since the swap file is then also encrypted. Most modern linux distro’s will behave in this way by default.
Ignore the first dd command since it contains a typo (shown)
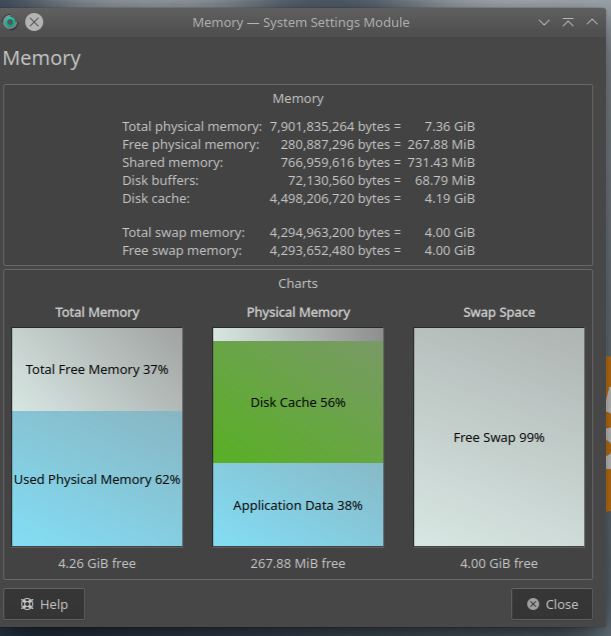
If you’re using KDE Plasma as your desktop environment, for entertainment purposes, open Memory.
The Memory Information dialog opens to look like this.
Now expand the window by dragging a corner and you’ll see some neat graphs of memory usage…
Memory and Swap Usage graphs in KDE Plasma Desktop Environments “Memory” app
Now with your Konsole to one side of the graphs, observe the changes going on on the system as you execute each command. Really quite cool. KDE Plasma is great. By far my favourite desktop environment. I recommend it but live in it for a week and figure it all out since it’s quite comprehensive. You’ll likely not go back!
Did you like this? Tip cyberfella with Cryptocurrency
Download latest Windows 10 ISO from here and perform a Windows 10 Pro installation to a freshly procured virtual machine. Say No to pretty much everything. Log into your Microsoft account during installation if you have other synchronised Windows devices already.
If using Oracle Virtualbox, insert VirtualBox Guest Additions CD and install, Reboot VM
If using an Sun Microsystems/Oracle Keyboard, change Host Key to Alt Graph on Keyboard since there’s no Right-Ctrl key which is the default.
Search for Windows Updates, Check for Updates, Install Windows Updates, Reboot VM
Open Powershell as Administrator and run the following command taken from here
Remove components you don’t require by clicking on each button. The script to remove the feature will execute in the PowerShell console behind.
I like to install Rainmeters and I simply stick with the default meters/widgets so I can easily keep track of the VM resource consumption at a glance, if things should slow up..
This is a running list of optimizations I’ve made in the past on problematic Windows 10 desktop systems to speed them up/fix them.
remove avast AV remove avast VPN restore windows defender AV remove windows c++ check startup programs, remove superflouous items analyze and defrag hard disk reset windows updates remove transparency effects install rainmeter and fix items to desktop make rainmeters disappear on mouse over install brave browser remove immediate access to MS Edge browser set dark themes in windows and brave change power settings to optimize for performance change power settings to not power down or sleep when plugged in change windows updates to dynamically adjust times when it performs windows updates based on usage change display effects to remove all special effects apart from drop shadows and show window contents when dragging. Disabled Windows Search Service (Search Indexing) Enable restart and notification for restart when Windows Updates needs it troubleshoot windows updates. system installed updates on restart feature update to windows 10 version 2004 being prepared. leave laptop on to complete. Synced time and set system to sync region automatically Run cmd as admin, run SFC /scannow to check for missing / damaged system files. Some found and repaired.
Did you like this? Tip cyberfella with Cryptocurrency
This post contains the steps to setup a private Ethereum blockchain.
First, you’ll need a Linux vm. Please note that this post assumes a medium/advanced level of knowledge. As such, it will be much more succinct than most posts in other categories.
INSTALL ETHEREUM
sudo apt-get install software-properties-commonAdd the ethereum repository: sudo add-apt-repository -y ppa:ethereum/ethereumUpdate the package list and upgrade entire systemInstall Ethereum.
If your genesisblock.json file is correctly written, the block will initialize with “Successfully wrote genesis state” message.
CHAINDATAAND LIGHTCHAINDATA
The chaindata and lightchaindata directories in geth indicate that your blockchain network has been created.
cd into ~/privatechain/geth and you’ll see chaindata and lightchaindata subdirectoriesThe genesis block.
MINING THE BLOCK
geth -datadir “/home/matt/privatechain” -mine
While the first block is being mined, ethers will be being added to your address. It may take a while depending on your parameters set in your genesisblock.json file
Typical output seen during mining
Now that mining has begun, you can see the new files that have appeared in the privatechain filesystem
geth.ipc transactions.rlp and the .ldb database files appear once the genesis block has been mined
SUMMARY
The steps performed above can be summarised as follows.
You can stop the mining process using the miner.stop() command
SMART CONTRACTS
“Smart contracts” is the name to describe a program that is compiled to execute on the blockchain network. Such programs running on Ethereum blockchains are written in the Solidity language.
chmod +x the ganache appimage file and execute it.
chmod +x ganache to allow execution of it
GANACHE
Enable/Disable analytics and click ContinueClick on QuickstartChange Port Number to 8545 for use with Metamask or Brave Crypto Wallet Browser extensionEnable Crypto Wallets in Brave BrowserClick the option to Restore a Local Wallet
Enter the seed phrase from Ganache into the Seed phrase field in Brave
Copy and Paste this into the Restore Seed Phrase field in Brave Crypto Wallet Restore and set a new password for the wallet.Once your wallet is displayed, change the Ethereum MainNet to Localhost:8545 to connect to the Ganache private blockchain.
Connect to the local Ethereum blockchain network on port 8545 (Ganache’s internal eth network) and you’ll see an initial balance of 100 ETH tokens.
Click on the coloured icon next to Localhost:8545 and Import a Wallet
In Ganache, click on the Key icon on one of the wallets (choose the 2nd one in the list of pre-configured wallets). Copy and Paste the private key into the Import screen shown above.
Copy and Paste the private key of the first ganache ethereum wallet into the Browser Crypto Wallet ImporterYou’ll import the 2nd wallet, so now Brave displays the balance of the first and second Ganache wallets. Ganache comes with a few more wallets for you to play with in your private ethereum development network.
You can see in the screenshot above, two Accounts have been imported, each with a balance of 100 ETH tokens. You can import as many of the ETH wallets from Ganache as you like/need for your Solidity Smart Contract project.
Since Ganache is connected to our local private blockchain running on our localhost on port 8545, you can see the details of the genesis block in the BLOCKS section
REMIX SOLIDITY IDE
Next we need an IDE for creating code when developing, compiling and deloying Solidity smart contracts that will use our connected wallets to pay the gas fees required to store the smart contract on our private blockchain. Remix is a web-based IDE for this purpose.
The web based Remix IDE for Solidity smart contracts running on Ethereum blockchains.Click on the Deploy and Run Transactions icon (shown) in the left-most panel, select Injected Web 3 and it’ll attempt to connect to your Brave Crypto Wallet. Tick the ETH wallet you want it to use and Authorise the connection of the wallet to Remix. Note that any actual transactions invoked when deploying compiled smart contract code as byte code to the private blockchain will still require manual authorisation by the wallet owner.Note that none of the pre-defined smart contracts have yet been compiled into bytecode so cannot be executed using our connected wallet. Click on the Compiler icon (shown) in the left-most panel and compile the smart contract.The successfully compiled files can be deployed.
Compile all the scripts 1_Storage, 2_Owner, 3_Ballot and 4_Ballot_Test files. Deploy the 4_Ballot_Test file.
CONFIRM TRANSACTIONS
The connected wallet will prompt for a confirmation for the transaction.
The transactions in the smart contract will require confirmation by the owner of the connected wallet before being submitted to the private blockchain we created earlier where they’ll be mined.
AUDIT TRANSACTIONS STORED IN MINED BLOCKS
The genesis block and our two transactions above can be seen in the BLOCKS tab in Ganache.
In Ganache that we connected to our local private Ethereum blockchain, you can click on the BLOCKS section and see the mined blocks that contain our recent two transactions, the date stamp of the transaction and gas used.
Click on the transactions button for each mined block to see the details of the transaction in that block.You can view the transactions in the TRANSACTIONS section if you don’t know what BLOCK contains it in the BLOCKS section.
SUMMARY
So far, we have…
Installed Ethereum
Created a private Ethereum blockchain on our localhost
Initialised the private blockchain
Mined the Genesis block in our private blockchain
Installed Ganache and connected it to our private blockchain
Imported two of the ETH wallets in Ganache to our Web Browser’s crypto wallet extension
Connected to Remix Solidity Smart Contract IDE
Connected Remix to one of our ETH Wallets
Compiled some Solidity Code Smart Contracts
Deployed the BallotTest smart contract to our private blockchain, confirming the transactions and accepting the gas fees.
Audited the mined blocks containing our transactions in Ganache
EXTRAS
The other smart contracts were compiled and deployed, and new blocks containing those transactions show up in Ganache.
The blocks in our private blockchainThe transactions in the blocks on our private blockchainThe transaction data contained in the contract creation transactionThe resulting balance in our connected ETH wallet used to pay the gas fees on the networkThe transactions in our wallet.
FINAL WORD
Note that all this information is referenced from the same blockchain, instead of the necessity of trusted third parties storing the same data in multiple places that could be changed and a conflict introduced into the history of the transactions in potentially mismatched ledgers. In addition to having an accurate central ledger that all parties reference, we can introduce more nodes in our network that each maintain a copy of the same blockchain.
The public ETH network that maintains the main net has many thousands of ETH nodes. It is this decentralised consensus that gives the value to blockchain, along with public keys being used to verify that the parties transacting have the necessary funds without revealing the private keys necessary to unlock those funds to the public internet.
The input and outputs between the wallet addresses are performed by the closed network, keeping everybody safe. The issuance of new coins is also controlled by the network to prevent abuse of the inflation rate that could affect the purchasing value of the tokens by driving the value down by diluting the supply ad infinitum (hyper inflation caused by excessive quantitative easing, effectively) .
Did you like this? Tip cyberfella with Cryptocurrency
Originally developed by Hashicorp, Terraform allows you to define your infrastructure, platform and services using declarative code, i.e. you tell it what scenario you want to get to, and it takes care on the in-between steps in getting you there.
CODE PHASE
E.g., if you wanted to get from a current state of “nothing” to a state of “virtual machine (vm)” and “kubernetes cluster (k8s)” networked together by a “virtual private cloud (vpc)”, then you’d start with an empty terraform file (ascii text file with an extension of .tf) and inside there’d be three main elements, the vm, the k8s cluster and the vpc above. This is called the “Code” phase.
PLAN PHASE
The plan phase compares the current state with the desired state, and forms a plan based on the differences, i.e. we need a VM, we need a K8s cluster and we need a VPC network.
APPLY PHASE
Next, is the Apply phase. Terraform works against the Cloud providers using real API’s, your API token, spin up these resources and output some autogenerated output variables along the way such as the kubernetes dashboard URL etc
PLUGGABLE BY DESIGN
Terraform has a strong open source community and is pluggable by design. There are modules and resources available to connect up to any IAAS cloud provider and automate the deployment of infrastructure there.
Although Terraform is widely considered to support the provisioning of Infrastructure as code from various Infrastructure as a Service (IaaS) cloud providers, it has expanded its use cases into Platform as Service (PaaS) and Software as a Service (SaaS) areas as well.
DEVOPS FIRST
Terraform is a DevOps tool. that is designed and works with the DevOps feedback loop in mind. i.e. If we take our desired scenario above of a VPC, VM and Kubernetes cluster and decide that we want to add a load balancer, then we would add a Load Balancer requirement to the .tf file in the code phase and the plan phase would compare the current state and see that the load balancer is the only change / only new requirement. By controlling the infrastructure using code in the terraform pipeline instead of directly configuring and changing the infrastructure away from it’s original terraform “recipe”, you can avoid “configuration drift”. This is called a “DevOps first” approach and is what gives us the consistency and scalability we want from a cloud based infrastructure, managed using DevOps practices.
INFRASTRUCTURE AS CODE
These days it’s increasingly important to automate your infrastructure as applications can be deployed into production hundreds of times a day. In addition, infrastructure is fleeting and can be provisioned or de-provisioned according to the demand to provide the service that meets customer requirements but also keep control of costs from cloud providers.
IMPERATIVE vs DECLARATIVE APPROACH
An imperative approach allows you to storyboard and define how your infrastructure is provisioned from nothing through to the final state, using a CLI in say, a bash script. This is great for recording how the infrastructure was initially provisioned, and can also make creating similar environments for testing etc but it doesn’t scale well and you are still at risk of others making undocumented changes that send your Dev, Test etc environments out of sync (they should always match) and risks that afore mentioned configuration drift.
So, we use a declarative approach instead, defining the FINAL STATE of the infrastructure using a tool like terraform, and letting the public cloud provider handle the rest. So instead of defining every step, you just define the final state.
IMMUTABLE vs MUTABLE INFRASTRUCTURE
Imagine a scenario where you have your scripts and you run them to get to v1.0 of your infrastructure. You then have a new requirement for a database to be added to the current infrastructure mix of VPC, VM and K8s elements. So, you modify your declarative code, execute it against your existing Dev environment, then assuming you’re happy, make the same change to 100 or 1000 other similar environments, only for it to not work properly, leaving you in a configuration drift state.
To eliminate the risk of this occurring, we can copy and modify our original code that got us to v1.0 and then execute it to create an entirely new and separate v2.0 state. This also ensures that your infrastructure can move to scale. It is expensive while there are v1.0 and v2.0 infrastructures running simultaneously but is considered best practice, and you can always revert to the v1.0 which remains running while v2.0 is deployed.
So, this immutable infrastructure approach, i.e. can not be changed/mutated once deployed, is preferable in order to reduce/eliminate risks with changing mutable infrastructure.
INSTALLING TERRAFORM
I found that terraform was not available via my package repositories, nor from my Software Manager on Linux Mint. So, I downloaded the Linux 64 bit package of the hour from terraform’s website
Unzipping the downloadable reveals a single executable file, terraform.After unzipping terraform, move the executable to /usr/local/bin
I’m using an AWS account, so I’ll need to use the AWS Provider in Terraform.
Next create a .tf file for our project that will initialize the terraform aws provider in the aws region we want and run the terraform init command.
#OpenShot Terraform Project
provider "aws" {
region = "eu-west-2"
}
Our openshot.tf file simply declares the provider (aws) and the region and is read by the terraform init command executed in the same directory.Initialization takes a few seconds.
If you haven’t already got one then you’ll need to set up an account on aws.amazon.com. It uses card payment data but is free for personal use for one year. The setup process is slick as you’d expect from amazon, and you’ll be up and running in just a few minutes.
In your AWS Cloud Management Console, Click Services, EC2.Click Instances, Launch Instance.Click AWS Marketplace and search for openshot
We don’t need to select it since we’re using terraform to build our infrastructure as code, so we can have terraform perform this search. The OpenShot AMI is a terraform DataSource AMI since its an image that already exists – not a Resource AMI i.e. we’re using an existing AMI not creating a new one. Terraform can perform this search for us in our .tf file.
Note that the documentation on terraform’s website uses /d/ or /r/ in the URL for datasources and resources of similarly named elements.
Copy and paste the example code into our openshot.tf file and make a few adjustments to allow access from http and ssh. Note that you should restrict SSH access to your own IP address to prevent exposing your SSH server to the world.
#OpenShot Terraform Project
provider "aws" {
region = "eu-west-2"
}
data "aws_ami" "openshot_ami" {
most_recent = true
owners = ["aws-marketplace"]
filter {
name = "name"
values = ["*OpenShot*"]
}
}
resource "aws_security_group" "openshot_allow_http_ssh" {
name = "openshot_allow_http_ssh"
description = "Allow HTTP and SSH inbound traffic"
ingress {
description = "Inbound HTTP Rule"
from_port = 80
to_port = 80
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
description = "Inbound SSH Rule"
from_port = 22
to_port = 22
protocol = "tcp"
#NOTE: YOU SHOULD RESTRICT THIS TO YOUR IP ADDRESS!
cidr_blocks = ["0.0.0.0/0"]
}
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
tags = {
Name = "openshot_allow_http_ssh"
}
}
We need to configure a Key Pair for our Amazon EC2 Instance for the SSH to ultimately work. We’ll return to this later when we configure the EC2 instance details in the openshot.tf file we’re constructing.
Configure a SSH Key Pair here.Creating an SSH keypair for our openshot project
Save the openshot-ssh.pem file to your project folder when prompted.
TERRAFORM PLAN
Next, we can test this with the terraform plan command.
terraform plan fails at this stage as we’ve not specified the credentials for our AWS account.
AWS CREDENTIALS
The AWS credentials can be specified as environment variables or in a shared credentials file in your home directory in ~/.aws/credentials more on the options here
The ~/.aws/credentials file can be created by installing the awscli package from your repositories, and running aws configure
Note that you should create an IAM user in your Amazon Management Console, and not create credentials for your aws root user account. I have created an account called matt for example. You’ll receive an email with a 12 digit ID for each IAM user which you’ll need to log in as well as the username and password for that user. The root user just uses an email address and password to log in.
Once you’ve logged in to your AWS Management Console, the credentials are obtained here…
Click on your account user@<12-digit-number>, My Security Credentials
After pasting the Access Key ID in, you’ll be asked for the Secret key next. In the event you don’t have it, you can simply CTRL-C out of aws configure, go back to the aws management console and generate a new one. You’ll only be shown the private key one time, so be sure to copy it, then re-run aws configure and enter the new access key id and secret key. I specified eu-west-2 (London) as my default location and json as my output format.
Note that the credentials are stored in plain text in ~/.aws.credentials
Depending on your situation, you may be able to Deactivate the previous Access Key ID and delete it from AWS Management Console if it’s never going to be used.
TERRAFORM PLAN USING CREDENTIALS FILE
Now if we re-run our terraform plan we see it succeeds.
re-run terraform plan and this time it used the creds found in ~/.aws/credentials
You can see that the Plan outcome at the end is 1 to add, 0 to change, 0 to destroy.
EC2 INSTANCE
Now we’re ready to specify our EC2 Instance and we just need the final section and edit it as shown below based on the data source and resource names specified elsewhere in the terraform file, adding key_name=”openshot-ssh” to refer to our .pem file we created earlier when we generated a SSH key pair for the EC2 Instance on the AWS Management console.
Re-running terraform plan shows our openshot ami resource on our aws ec2 instanceand ends with the message Plan: 2 to add, 0 to change, 0 to destroy.
OUTPUT
Lastly, we can add an output section that outputs the public IP for our OpenShot AMI
output "IP" {
value = "${aws_instance.web.public_ip}"
}
TERRAFORM APPLY
When our terraform plan is ready, we can execute the command terraform apply and terraform will re-execute terraform plan before prompting for input prior to executing the script against the aws cloud provider and building our infrastructure.
terraform apply
Did you like this? Tip cyberfella with Cryptocurrency
Here are some Linux commands that everyone should be familiar with. In fact, you could argue that these are the first commands to memorise and build out your repertoire from there.
#BASIC LINUX COMMANDS
#Clear the terminal window
clear
#Show kernel version
uname -a
#Show all tunable kernel parameters in the /proc/sys directory
sudo /sbin/sysctl -a
#Set a kernel parameter on the fly without persistence
sudo /sbin/sysctl -w kernel.sysrq="1"
#Set a kernel parameter with persistence
/etc/sysctl.conf
#Kernel parameters startup script
/etc/rc.d/rc.sysinit
#Show network interfaces
ifconfig
ip addr show
#Configure network interface with persistence
/etc/sysconfig/network
/etc/sysconfig/network-scripts/ifcfg-eth0
#Show all filesystems and space
df -ah
#Show service status
service udev status
systemctl status udev
#How much disk space is used by a given directory
du ~/Downloads
#What TCP and UDP ports is the listem listening on?
netstat -tulpn
sudo netstat -tulpn #gives more info on process name
#Show information about a given process
ps aux | grep containerd
#Show free memory stats
free
#List block storage devices known to the system
lsblk
#Show mounted storage devices
mount
#Show filesystems that should be mounted at boot
cat /etc/fstab
#Mount everything in /etc/fstab
mount -a
#Mount a block storage device
mount /dev/sdb1 /mnt
#LVM Commands
pvdisplay pvcreate pvremove pvchange
vgdisplay vgcreate vgextend vgremove vgchange
lvdisplay lvcreate lvextend lvremove lvchange
mkfs.ext4
#Copy files
cp
rsync
dd
#Show command history
history
#Look up a command
man -k <search-string>
man grep
Did you like this? Tip cyberfella with Cryptocurrency