

Here is a handy cheat sheet in troubleshooting failing backups and recoveries using Dell/EMC Networker. All content here is taken from real-world experience (and is regularly updated).

Is backup server running?
Check the uptime and that the daemon log is being written to.
nsrwatch -s backupserver -Gives a console version of the NMC monitor
cp /nsr/logs/daemon.raw ~/copyofdaemon.raw nsr_render_log -l ~/copyofdaemon.raw > ~/copyofdaemon.log tail -10 ~/copyofdaemon.log
You may find mminfo and nsradmin commands are unsuccessful. The media database may be unavailable and/or you may receive “program not registered” error that usually implies the Networker daemons/services are not running on the server/client. This can also occur during busy times such as clone groups running (even though this busy-ness is not reflected in the load averages on the backup server.
Client config.
Can you ping the client / resolve the hostname or telnet to 7937?
Are the static routes configured (if necessary).
Can the client resolve the hostnames for the backup interfaces? have connectivity to them?
Does the backup server appear in the nsr/res/servers file?
Can you run this on the client?
save -d3 -s /etc
From the backup server (CLI)…
nsradmin -p 390113 -s client
Note: If the name field is incorrect according to nsradmin (happens when machines are re-commissioned without being rebuilt) then you need to stop nsrexecd, rename /nsr/nsrladb folder to /nsr/nsrladb.old, restart nsrexecd, and most importantly, delete and recreate the client on the networker backup server, before retrying the following command:
savegrp -vc client_name group_name
Also check that all interface names are in the servers file for all interfaces on all backup servers and storage nodes likely to back the client up.
Can you probe the client?
savegrp -pvc client groupname savegrp -D2 -pc client groupname (more verbose)
Bulk import of clients
Instead of adding clients manually one at a time in the NMC, you can perform an initial bulk import.
nsradmin -i bulk-import-file
where the bulk-import-file contains many lines like this
create type: NSR Client;name:w2k8r2;comment:SOME COMMENT;aliases:w2k8r2,w2k8r2-b,w2k8r2.cyberfella.co.uk;browse policy:Six Weeks;retention policy:Six Weeks;group:zzmb-Realign-1;server network interface:backupsvrb1;storage nodes:storagenode1b1;
Use excel to form a large csv, then use Notepad++ to remove commas. Be aware there is a comma in the aliases field, so use an alternative character in excel to represent this then replace it with a comma once all commas have been removed from the csv.
Add user to admin list on bu server
nsraddadmin -u user=username, host=*
where username is the username minus the domain name prefix (not necessary).
Reset NMC Password (Windows)
The default administrator password is administrator. If that doesn’t work, check to see that the GST service is started using a local system account (it is by default), then in Computer Management, Properties, Advanced Properties, create a System Environment Variable;
GST_RESET_PW=1
Stop and start the GST Service and attempt to logon to the NMC using the default username and password pair above.
When done, set
GST_RESET_PW=<null>
Starting a Backup / Group from the command line
On the backup server itself:
savegrp -D5 -G <group_name>
Ignore the index save sets if you are just testing a group by adding -I
Just backing up the :index savesets in a group:
savegrp -O -G <group_name>
On a client:
save -s <backup_server_backupnic_name> <path>
Reporting with mminfo
List names of all clients backed up over the last 2 weeks (list all clients)
mminfo -q "savetime>2 weeks ago" -r 'client' | sort | uniq mminfo -q 'client=client-name, level=full' -r 'client,savetime,ssid,name,totalsize'
in a script with a variable, use double quotes so that the variable gets evaluated, and to sort on american date column…
mminfo -q "client=${clientname},level=full" -r 'client,savetime,ssid,level,volume' | sort -k 2.7,2.10n -k 2.1,2.5n -k 2.4,2.5n

mminfo -ot -c client -q "savetime>2 weeks ago" mminfo -r "ssid,name,totalsize,savetime(16),volume" -q "client=client_name,savetime >10/01/2012,savetime <10/16/2012"
List the last full backup ssid’s for subsequent use with recover command (unix clients)
mminfo -q 'client=server1,level=full' -r 'client,savetime,ssid'
Is the client configured properly in the NMC? (see diagram above for hints on what to check in what tabs)
How many files were backed up in each saveset (useful for counting files on a NetApp which is slow using the find command at host level)
sudo mminfo -ot -q 'client=mynetappfiler,level=full,savetime<7 days ago' -r 'name,nfiles'
name nfiles /my_big_volume 894084
You should probably make use of the ssflags option in the mminfo report too, which adds an extra column regarding the status of the saveset displaying one or more of the following characters CvrENiRPKIFk with the common fields shown in bold below along with their meanings.
C Continued, v valid, r purged, E eligible for recycling, N NDMP generated, i incomplete, R raw, P snapshot, K cover, I in progress, F finished, k checkpoint restart enabled.
Check Client Index
nsrck -L7 clientname
Backing up Virtual Machines using Networker,VCentre and VADP
To back up virtual machine disk files on vmfs volumes at the vmware level (as opposed to the individual file level backups of the individual vm’s), networker can interface with the vcenter servers to discover what vm’s reside on the esxi clusters managed by them, and their locations on the vmfs shared lun. For this to work, the shared lun’s also need to be presented/visible to the VADP Proxy (Windows server with Networker client and/or Server running as a storage node) in the fc switch fabric zone config.

The communication occurs as shown in blue. i.e.
The backup server starts backup group containing vadp clients.
The vadp proxy asks vcentre what physical esxi host has the vm, and where the files reside on the shared storage luns.
The vadp proxy / networker storage node then tells the esxi host to maintain a snapshot of the vm while the vmdk files are locked for backup.
the vmdk files are written to the storage device (in my example, a data domain dedup device)
when the backup is complete, the client index is updated on the backup server, and the changes logged by the snapshot are applied to the now unlocked vmdk and then the snapshot is deleted on the esxi host.
Configuring Networker for VADP Backups via a VADP Proxy Storage Node
The VADP Proxy is just a storage node with fibre connectivity to the SAN and access to the ESXi DataStore LUNs.
In Networker, right click Virtualisation, Enable Auto Discovery

Complete the fields, but notice there is an Advanced tab. This is to be completed as follows… not necessarily like you’d expect…
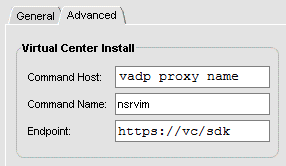
Note that the Command Host is the name of the VADP Proxy, NOT the name of the Virtual Center Server.
Finally, Run Auto Discovery. A map of the infrastructure should build in the Networker GUI

Ensure vc, proxy and networker servers all have network comms and can resolve each others names.
You should now be ready to configure a VADP client.
Configuring a VADP client (Checklist)
GENERAL TAB

IDENTITY
COMMENT
application_name – VADP
VIRTUALIZATION
VIRTUAL CLIENT
(TICK)
PHYSICAL HOST
client_name
BACKUP
DIRECTIVE
VCB DIRECTIVE
SAVE SET
*FULL*
SCHEDULE
Daily Full
APPS AND MODULES TAB

BACKUP
BACKUP COMMAND
nsrvadp_save -D9
APPLICATION INFORMATION
VADP_HYPERVISOR=fqdn_of_vcenter (hostname in caps)
VADP_VM_NAME=hostname_of_vm (in caps)
VADP_TRANSPORT_MODE=san
DEDUPLICATION
Data Domain Backup
PROXY BACKUP
VMWare
hostname_of_vadp_proxy:hostname_of_vcenter.fqdn(VADP)
GLOBALS 1 OF 2 TAB
ALIASES
hostname
hostname.fqdn
hostname_backup
hostname_backup.fqdn
ip_front
ip_back
GLOBALS 2 OF 2 TAB
REMOTE ACCESS
user=svc_vvadpb,host=hostname_vadp_proxy
user=SYSTEM,host=hostname_vadp_proxy
*@*
OWNER NOTIFICATION
/bin/mail -s “client completion : hostname_client” nwmonmail
Recovery using recover on the backup client
sudo recover -s backup_server_backup_interface_name
Once in recover, you can cd into any directory irrespective of permissions on the file system.
Redirected Client Recovery using the command line of the backup server.
Initiate the recover program on the backup server…
sudo recover -s busvr_interface -c client_name -iR -R client_name
or use… -iN (No Overwrite / Discard)
-iY (Overwrite)
-iR (Rename ~ )
Using recover> console
Navigate around the index of recoverable files just like a UNIX filesystem
Recover> ls pwd cd\
Change Browsetime
Recover> changetime yesterday
1 Nov 2012 11:30:00 PM GMT
Show versions of a folder or filename backed up
Recover> versions (defaults to current folder)
Recover> versions myfile
Add a file to be recovered to the “list” of files to be recovered
Recover> add
Recover> add myfile
List the marked files in the “list” to be recovered
Recover> list
Show the names of the volumes where the data resides
Recover> volumes
Relocate recovered data to another folder
Recover> relocate /nsr/tmp/myrecoveredfiles
Recover> relocate “E:\\Recovered_Files” (for Redirected Windows Client Recovery from Linux Svr)
View the folder where the recovered files will be recovered to
Recover> destination
Start Recovery
Recover> recover
SQL Server Recovery (database copy) on a SQL Cluster
First, rdc to cluster name and run command prompt as admin on cluster name (not cluster node)
nsrsqlrc -s <bkp-server-name> -d MSSQL:CopyOfMyDatabase -A <sql cluster name> -C MyDatabase_Data=R:\MSSQL10_50.MSSQLSERvER\MSSQL\Data\CopyOfMyDatabase.mdf,MyDatabase_log=R:\MSSQL_10_50\MSSQLSERVER\MSSQL\Data\CopyOfMyDatabase.ldf MSSQL:MyDatabase
Delete the NSR Peer Information of the NetWorker Server on the client/storage node.
Please follow the steps given below to delete the NSR peer information on NetWorker Server and on the Client.
1. At NetWorker server command line, go to the location /nsr/res
2. Type the command:
nsradmin -p nsrexec
print type:nsr peer information; name:client_name
delete
y
Delete the NSR Peer Information for the client/storage node from the NetWorker Server.
Specify the name of the client/storage node in the place of client_name.
1. At the client/storage node command line, go to the location /nsr/res
2. Type the command:
nsradmin -p nsrexec
print type:nsr peer information
delete
y
VADP Recovery using command line
Prereqs to a successful VADP restore are that the virtual machine be removed from the Inventory in VCenter (right click vm, remove from Inventory), and the folder containing the virtual machines files in the vmware datastore be renamed or removed. If the vm still exists in vmware or in the datastore, VADP will not recover it.
Log onto the backup server over ssh and obtain the save set ID for your VADP “FULLVM” backup.
mminfo –avot –q “name=FULLVM,level=full”
Make a note of the SSID for the vm/backup client (or copy it to the cut/paste buffer)
e.g. 1021210946
Log onto the VADP Proxy (which has SAN connectivity over fibre necessary to recover the files back to the datastore using the san VADP recover mode)
recover.exe –S 1021210946 –o VADP:host=VC_Svr;VADP:transmode=san
Note that if you want to recover a VM back to a different vCenter,Datastore,ESX host and/or different resource pool, you can do that from the recover command too, rather than waiting to do it using the vsphere client. this can be used if your vm still exists in vmware and you don’t want to overwrite it. You can additionally specify VADP:host= VADP:datacenter= VADP:resourcepool= VADP:hostsystem= and VADP:datastore= fields in the recover command, separated by semicolons and no spaces.
I’ve found that whilst the minimal command above may work on some environments, others demand a far more detailed recover.exe command with all VADP parameters set before it’ll communicate with the VC. A working example is shown below (with each VADP parameter separated on a newline for readability – you’ll need to put it into a single line, and remove any spaces between each .
recover.exe -S 131958294 -o
VADP:host=vc.fqdn;
VADP:transmode=san;
VADP:datacenter=vmware-datacenter-name;
VADP:hostsystem=esxihost.fqdn;
VADP:displayname=VM_DISPLAYNAME;
VADP:datastore=“config=VM_DataStore#Hard disk 2=VM_DataStore_LUN_Name#Hard disk 1=VM_DataStore_LUN_Name”;
VADP:user=mydomain\vadp_user;
VADP:password=vadp_password
Creating new DataDomain Devices in Networker
In Networker Administrator App from NMC Console, Click Devices button at the top.
Right click Devices in the Left hand pane, New Device Wizard (shown)

Select Data Domain, Next, Next

Use an existing data domain system
Choose a data domain system in the same physical location to your backup server!
Enter the Data Domain OST username and password

Browse and Select
Create a New Folder in sequence, e.g. D25, tick it.

Highlight the automatically generated Device Name, Copy to clipboard (CTRL-C), Next

Untick Configure Media Pools (label device afterwards using Paste from previous step), Next

Select Storage Node to correspond with device locality from “Use an existing storage node”, Next
Agree to the default SNMP info (unless reconfiguration for custom monitoring environment is required), Next
Configure, Finish
Select new device (unlabelled, Volume name blank), right click, Label

Paste Device Name in clipboard buffer (CTRL-V)
Select Pool to add the Device into, OK.

Slow backups of large amounts of data to DataDomain deduplication device
If you have ridiculously slow backups of large amounts of data, check in Networker NMC to see the name of the storage node (Globals2 tab of the client configuration), then connect to the DataDomain and look under the Data Management, DD Boost screen for “Clients” of which your storage node will be one. Check how many CPU’s and Memory it has. e.g. Guess which one is the slow one (below)

Then SSH to the storage node and check what processes are consuming the most CPU and Memory (below)

In this example (above), despite dedicating a storage node backup a single large applications data, the fact that it only has 4 cpu’s and is scanning every file that ddboost is attempting to deduplicate means that a huge bottleneck is introduced. This is a typical situation whereby decommissioned equipment has been re-purposed.
Networker Server
ssh to the networker server and issue the nsrwatch command. It’s a command line equivalent to connecting to the Enterprise app in the NMC and looking at the monitoring screen. Useful if you can’t connect to the NMC.

Blank / Empty Monitoring Console
If you’re NMC is displaying a blank monitoring console, try this before restarting the NMC…
Tick or Un-tick and Re-tick Archive Requests.

Tape Jukebox Operations
ps -ef | grep nsrjb -Maybe necessary to kill off any pending nsrjb processes before new ones will work. nsrjb -C | grep <volume> -Identify the slot that contains the tape (volume) nsrjb -w -S <slot> -Withdraw the tape in slot <slot> nsrjb -d -Deposit all tapes in the cap/load port into empty slots in the jukebox/library.
Note: If you are removing and replacing tapes you should take note what pools the removed tapes belong it and allocate new blank tapes deposited into the library to the same pools to eliminate impact on backups running out of tapes.
Exchange Backups
The application options of the backup client (exchange server in DAG1 would be as follows
NSR_SNAP_TYPE=vss NSR_ALT_PATH=C:\temp NSR_CHECK_JET_ERRORS=none NSR_EXCH2010_BACKUP=passive NSR_EXCH_CHECK=no NSR_EXCH2010_DAG=GB-DAG1 NSR_EXCH_RETAIN_SNAPSHOTS=no NSR_DEVICE_INTERFACE=DATA_DOMAIN NSR_DIRECT_ACCESS=no
Adding a NAS filesystem to backup (using NDMP)
Some pre-reqs on the VNX need to be satisfied before NDMP backups will work. This is explained here…
General tab

The exported fs name can be determined by logging onto the VNX as nasadmin and issuing the following command
server_mountpoint server_2 -list
Apps and Modules tab

Application Options that have worked in testing NDMP Backups.
Leave datadomain unticked in Networker 8.x and ensure you’ve selected a device pool other than default, or Networker may just sit waiting for a tape while you’re wondering why NDMP backups aren’t starting!
HIST=y UPDATE=y DIRECT=y DSA=y SNAPSURE=y #OPTIONS=NT #NSR_DIRECT_ACCESS=NO #NSR_DEVICE_INTERFACE=DATA_DOMAIN
Backup Command
nsrndmp_save -s backup_svr -c nas_name -M -T vbb -P storage_node_bu_interface or don't use -P if Backup Server acts as SN.
To back up an NDMP client to a non-NDMP device, use the -M option.
The value for the NDMP backup type depends on the type of NDMP host. For example, NetApp, EMC, and Procom all support dump, so the value for the Backup Command attribute is:
nsrndmp_save -T dump
Globals 1 tab

Globals2 tab

List full paths of VNX filesystems required for configuring NDMP save client on Networker (run on VNX via SSH)
server_mount server_2
List full paths required to configure NDMP backup clients (emc VNX)
server_mount server_2 e.g. /root_vdm_2/CYBERFELLA_Test_FS
Important: If the filesystem being backd up contains more than 5 million files, set the timeout attribute to zero in the backup group’s properties.
Command line equivalent to the NMC’s Monitoring screen
nsrwatch
Command line equivalent to the NMC’s Alerts pane
printf "show pending\nprint type:nsr\n" | /usr/sbin/nsradmin -i-
Resetting Data Domain Devices
Running this in one go if you’ve not done it before is not advised. Break it up into individual commands (separated here by pipes) and ensure the output is what you’d expect, then re-join commands accordingly so you’re certain you’re getting the result you want. This worked in practice though. It will only reset Read Only (.RO) devices so it won’t kill backups, but will potentially kill recoveries or clones if they are in progress.
nsr_render_log -lacedhmpty -S "1 hour ago" /nsr/logs/daemon.raw | grep -i critical | grep RO | awk {'print $10'} | while read eachline; do nsrmm | grep $eachline | cut -d, -f1 | awk {'print $7'}; done | while read eachdevice; do nsrmm -HH -v -y -f "${eachdevice}"; done
Identify OS of backup clients via CLI
The NMC will tell you what the Client OS is, but it won’t elaborate and tell you what type, e.g. Solaris, not Solaris 11 or Linux, not Linux el6. Also, as useful as the NMC is, it continually drives me mad how you cant export the information on the screen to excel. (If someone figures this out, leave a comment below).
So, here’s how I got what I wanted using the good ol’ CLI on the backup server. Luckily for me the backup server is Linux.
Run the following command on the NetWorker server, logging the putty terminal output to a file:
nsradmin . type: nsr client show client OS type show name show os type p
This should get you a list of client names and what OS they’re running according to Networker in your putty.log file. Copy and paste the list into a new file called mylist. Extract just the Solaris hosts…
grep -i -B1 solaris >mylist grep name mylist | cut -d: -f2 | cut -d\; -f1 >mysolarislist sed 's/^ *//' mysolarislist | grep -v \\-bkp > solarislist
You’ll now have a nice clean list of solaris networker client hostnames. You can remove any backup interface names by using
grep -v b$
to remove all lines ending in b.
One liner…
grep -i -B1 solaris mylist | grep name | cut -d: -f2 | cut -d\; -f1 | sed 's/^ *//' | grep -v \\-bkp | grep -v b$ | sort | uniq > solarislist
Now this script will use that list of hostnames to ssh to them and retrieve more OS detail with the uname -a command. Note that if SSH keys aren’t set up, you’ll need to enter your password each time a new SSH session is established. This isn’t as arduous as it sounds. use PuTTY right click to paste the password each time, reducing effort to a single mouse click.
#!/bin/bash
cat solarislist | while read eachhost; do
echo "Processing ${eachhost}"
ssh -n -l cyberfella -o StrictHostKeyChecking=no ${eachhost} 'uname -a' >> solaris_os_ver 2>&1
done
This generates a file solaris_os_ver that you can just grep for ^SunOS and end up with a list of all the networker clients and the full details of the OS on them.
grep ^SunOS solaris_os_ver | awk '{print $1 $3 $2}'
Tip cyberfella with Cryptocurrency
Donate Bitcoin to cyberfella

Donate Bitcoin Cash to cyberfella

Donate Ethereum to cyberfella
Donate Litecoin to cyberfella
Donate Monero to cyberfella

Donate ZCash to cyberfella
